

研究背景
数据投毒攻击可以被定义为一个双层优化的问题,如下公式1
$$L_{\text{adv}}(D_{\text{adv}}; \arg \min_{\theta} L_{\text{train}}(D_{\text{clean}}\cup D_{\text{poison}}; {\theta}))$$
说人话就是基于原始干净的数据集$D_{claen}$和投毒数据集$D_{poison}$,在给定的损失函数$L_{train}$下进行优化获得模型更新后的参数$\theta$。$D_{adv}$是一个测试对抗样本集合,$L_{adv}$是和投毒目标相关的损失函数,攻击者希望通过数据投毒在训练好的参数$\theta$和对抗样本集合$D_{adv}$上获得的损失$L_{adv}$最小。
下面是相关伪代码
class Model:
def __init__(self):
# 初始化模型
...
def forward(self, x):
# 前向传播
...
def train(model, D_clean, D_poison, optimizer):
# 训练模型
data = D_clean + D_poison # 合并干净数据集和投毒数据集
L_train = ... # 定义训练损失函数
optimizer.zero_grad() # 清空梯度
L_train.backward() # 反向传播
optimizer.step() # 更新模型参数
# 保存模型
save_model(model)
def poison(model, D_adv, optimizer):
# 加载已训练的模型
# D_adv 是对抗样本集合
L_adv = ... # 定义与投毒目标相关的损失函数
optimizer.zero_grad() # 清空梯度
L_adv.backward() # 反向传播
optimizer.step() # 更新模型参数
# 保存攻击后的模型
save_model(model)
# 假设 D_clean, D_poison, D_adv 是数据集,optimizer 是优化器
model = Model()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练阶段
train(model, D_clean, D_poison, optimizer)
# 投毒阶段
poison(model, D_adv, optimizer)为了解决双层优化问题,前人提出了很多优化算法,在此我们只介绍连续空间投毒样本优化的Metapoison算法
Metapoison算法
对于公式1,我们可以将内层优化问题作为约束条件得到公式2。
$$arg \min_{D_{poison}\in D} L_{adv}(D_{adv};{\theta})$$ $$\qquad s.t. \quad {\theta} = \arg \min_{\theta} L_{\text{train}}(D_{\text{clean}}\cup D_{\text{poison}}; {\theta}))$$
基于公式2,Metapoison得到了公式3。
$$arg \min_{D_{poison}\in D} L_{adv}(D_{adv};{\theta_2})\\$$ $$ s.t. \quad {\theta}_1 = {\theta}_0 - {\alpha}\nabla_{D_{poison}} L_{train}(D_{\text{clean}}\cup D_{\text{poison}}; {\theta_0})$$ $$ {\theta}_2 = {\theta}_1 - {\alpha}\nabla_{D_{poison}} L_{train}(D_{\text{clean}}\cup D_{\text{poison}}; {\theta_1})$$
PS:$\nabla$表示梯度
我们发现这个公式3和我们机器学习的梯度下降算法(公式4)比较像
$$\theta_k = \theta_{k-1} - \eta \nabla_{\theta} J(\theta_{k-1})$$
梯度下降的伪代码
# 计算偏导也就是梯度
theta = ...
for i in range(n):
d_theta = compute_gradient(theta)
theta = theta - eta * d_theta
...所以Metapoison的伪代码也差不多类似
# 计算偏导也就是梯度
theta = ...
for i in range(n):
d_theta = compute_gradient(theta)
theta_1 = theta_0 - alpha * L_train
theta_2 = theta_1 - alpha * L_train
...
# 得到theta_2后,就可以进行最外层对theta_2的优化了Metapoison的完整框架
算法:基于Metapoison针对于目标网络生成投毒数据
输入:$(X, Y), x_t, y_{adv}, n<<N,T,M$
输出:$X_p$
训练$M$个模型,其中第$m$个模型训练到第$mT/M$轮,获得参数$\theta_m$,从训练集中选择$n$幅图像作为修改的投毒样本并用$X_p$表示,剩余的干净样本用$X_c$表示。
$$For \quad i=1,...,C\quad (迭代次数) $$ $$ \quad For \quad m=1,...,M\quad (模型个数)$$ $$ \qquad \hat{\theta} \gets {\theta}_m $$ $$ \qquad For \quad k=1,...,K\quad (展开步数) $$ $$ \qquad \quad \hat{\theta}=\hat{\theta} - {\alpha}\nabla_{\hat{\theta}} L_{train}(X_{c}\cup X_{p},Y; \hat{\theta}) $$ $$ \qquad 对抗损失:L_m = L_{adv}(x_i,y_{adv};\theta_m) $$ $$\qquad 训练当前模型:\theta_m = \theta_m-{\alpha}\nabla_{{\theta}_m} L_{train}(X_,Y; \theta_m)$$ $$ \qquad如果当前模型训练到第T+1轮,则将其重新初始化$$ $$ \quad 将所有对抗损失取平均值:L_{adv}=\sum_{m=1}^ML_m/M$$ $$ \quad 基于L_{adv}计算梯度并更新X_p $$ $$ 返回获得的投毒数据集X_p$$
算法整体分为两个阶段
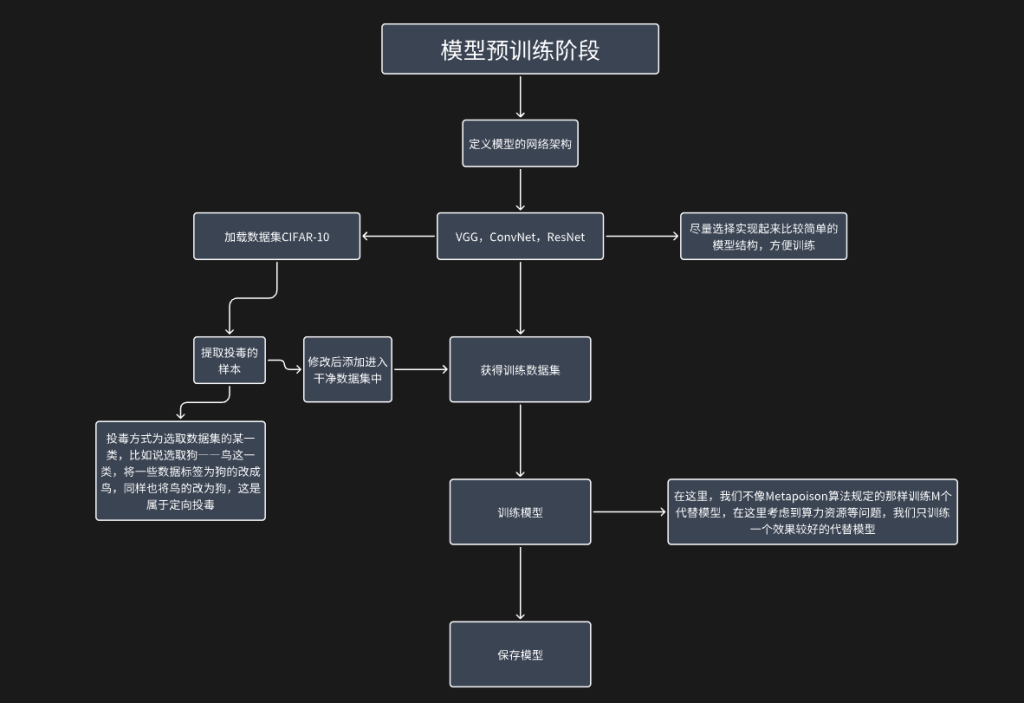
(一)模型预训练阶段
训练$M$个代替模型,将第$m$个代替模型训练$mT/M$轮,这里训练多个模型是为了增加模型的多样性,以此尽可能提升生成的投毒数据的迁移能力。
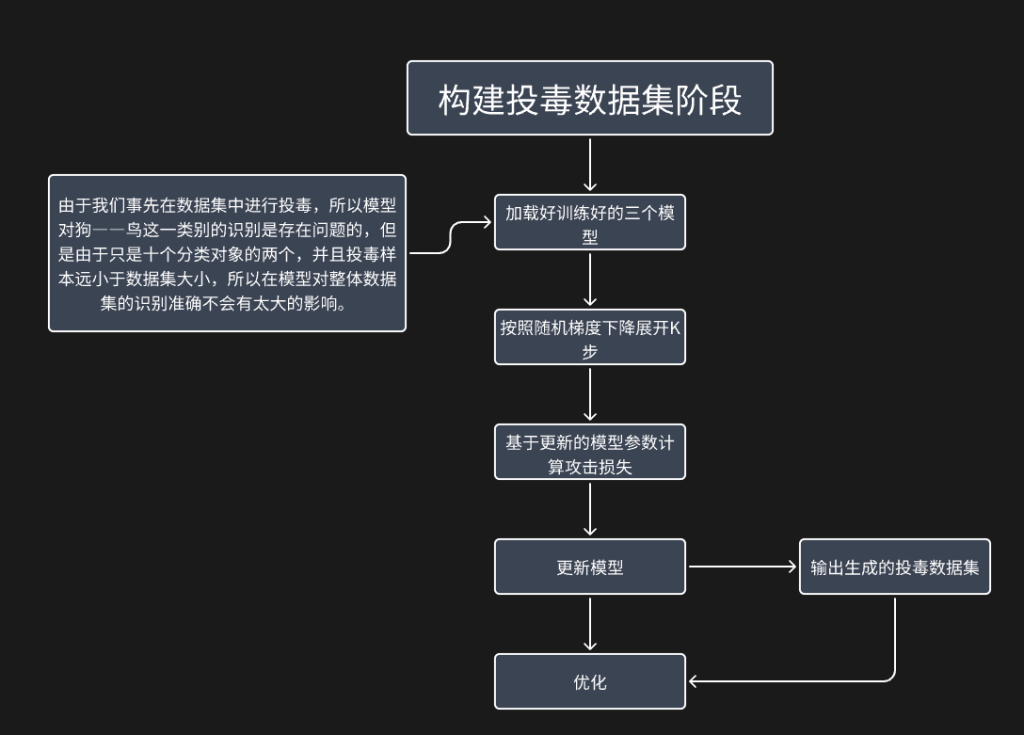
(二)构建投毒数据阶段
使用预训练好的$M$个代替模型进行攻击,并获得投毒数据集。对于每一个替代模型,首先,按照随机梯度下降展开$K$步,然后基于更新后的模型参数计算,外层对抗样本攻击损失,并将当前替代模型更新一轮,最后,在所有替代模型更新完成后,获得所有对抗损失的平均值,对投毒数据集进行优化。
攻击效果分析
| 投毒样本个数(比例) | 分类准确率 | 攻击成功率 | |
| ConNetBN | 1(0.002%) | 0.7322 | 0.00 |
| 10(0.02%) | 0.7271 | 0.03 | |
| 100(0.2%) | 0.7197 | 0.31 | |
| 500(1.0%) | 0.7132 | 0.76 | |
| 5000(10%) | 0.7023 | 0.85 |
| 投毒样本个数(比例) | 分类准确率 | 攻击成功率 | |
| VGG | 1(0.002%) | 0.7122 | 0.00 |
| 10(0.02%) | 0.7071 | 0.06 | |
| 100(0.2%) | 0.7097 | 0.45 | |
| 500(1.0%) | 0.6982 | 0.44 | |
| 5000(10%) | 0.6935 | 0.72 |
| 投毒样本个数(比例) | 分类准确率 | 攻击成功率 | |
| ResNet | 1(0.002%) | 0.7722 | 0.02 |
| 10(0.02%) | 0.7671 | 0.05 | |
| 100(0.2%) | 0.7697 | 0.24 | |
| 500(1.0%) | 0.7532 | 0.68 | |
| 5000(10%) | 0.7323 | 0.76 |
参考资料
- 腾讯安全朱雀实验室. (2022). AI安全:技术与实战. 电子工业出版社. ISBN: 978-7-121-43926-1.
- MetaPoison: Practical General-purpose Clean-label Data Poisoning
- https://github.com/wronnyhuang/metapoison?tab=readme-ov-file
Comments NOTHING