

对抗样本定义
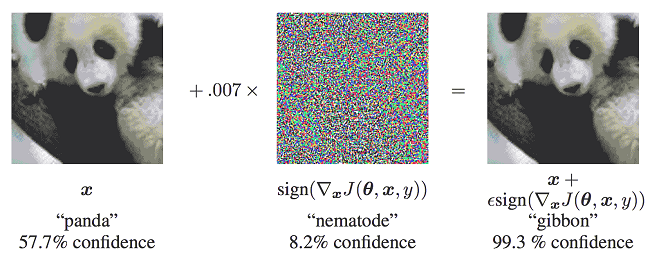
Szegedy在2013年最早提出对抗样本的概念:在原始样本处加入人类无法察觉的微小扰动,使得深度模型性能下降,这种样本即对抗样本。如下图所示,本来预测为“panda”的图像在添加噪声之后,模型就将其预测为“gibbon”,右边的样本就是一个对抗样本:
攻击方法
对模型的攻击方法可以按照以下方法分类:
- 攻击者掌握的信息多少:
1.1 白盒攻击:攻击者具有对模型的全部知识和访问权限,包括模型结构、权重、输入、输出。攻击者在产生对抗性攻击数据的过程中能够与模型系统有所交互。攻击者可以针对被攻击模型的特性设计特定的攻击算法。
1.2 黑盒攻击:与白盒攻击相反,攻击者仅具有关于模型的有限知识。攻击者对模型的结构权重一无所知,仅了解部分输入输出。
- 攻击者的目的:
2.1 有目标的攻击:攻击者将模型结果误导为特定分类。
2.2 无目标的攻击:攻击者只想产生错误结果,而不在乎新结果是什么。
本案例中用到的FGSM是一种白盒攻击方法,既可以是有目标也可以是无目标攻击。
更多的模型安全功能可参考MindArmour,现支持FGSM、LLC、Substitute Attack等多种对抗样本生成方法,并提供对抗样本鲁棒性模块、Fuzz Testing模块、隐私保护与评估模块,帮助用户增强模型安全性。
快速梯度符号攻击(FGSM)
正常分类网络的训练会定义一个损失函数,用于衡量模型输出值与样本真实标签的距离,通过反向传播计算模型梯度,梯度下降更新网络参数,减小损失值,提升模型精度。
FGSM(Fast Gradient Sign Method)是一种简单高效的对抗样本生成方法。不同于正常分类网络的训练过程,FGSM通过计算loss对于输入的梯度$J(\theta, x, y)$,这个梯度表征了loss对于输入变化的敏感性。然后在原始输入加上上述梯度,使得loss增大,模型对于改造后的输入样本分类效果变差,达到攻击效果。对抗样本的另一要求是生成样本与原始样本的差异要尽可能的小,使用sign函数可以使得修改图片时尽可能的均匀。
产生的对抗扰动用公式可以表示为:
$$\eta = \varepsilon \cdot \text{sign}(\nabla_x J(\theta))$$
对抗样本可公式化为:
$$x' = x + \epsilon \cdot \text{sign}(\nabla_x J(\theta, x, y))$$
其中,
- $x$:正确分类为“Pandas”的原始输入图像。
- $y$:是xx的输出。
- $θ$:模型参数。
- $ε$:攻击系数。
- $J(\theta, x, y)$:训练网络的损失。
- $J(\theta)$:反向传播梯度。
Model
from torch import nn
from torch.nn import functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 10, 5)
self.conv2 = nn.Conv2d(10, 20, 5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)训练过程
import torch
from torch import nn
from model import LeNet
def train(train_loader, epoch, device):
model = LeNet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for i in range(epoch):
train_loss = 0
model.train()
for idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
output = model(data)
loss = loss_fn(output, target)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'train loss: {train_loss / len(train_loader)}')
print(f'train loss: {train_loss}')
now_loss = train_loss
least_loss = 0
if now_loss < least_loss:
least_loss = now_loss
torch.save(model.state_dict(), f='model/LeNet_mnist_model.pth')攻击过程
import torch
from matplotlib import pyplot as plt
from torch.nn import functional as F
from model import LeNet
from train import train
from torch import nn
from torchvision import transforms
from torchvision.datasets import MNIST
# define a FGSM module
def fgsm_attack(image, epsilon, data_grad):
# to find loss about derivative of input, and sign it (符号化),基于符号的梯度法
data_grad = data_grad.sign()
# use epsilon to create adversarial examples
preturbed_image = image + epsilon * data_grad
# carry out cutting work, to change numeric bigger than 1 to 1, smaller than 0 to 0 in image inner
# prevent images from going out of bounds
preturbed_image = torch.clamp(preturbed_image, 0, 1)
# return adversarial examples
return preturbed_image
# define the attack process
def attack(model, device, test_loader, epsilon):
correct = 0
adv_examples = []
for data, target in test_loader:
data, target = data.to(device), target.to(device)
data.requires_grad = True
output = model(data)
init_pred = output.max(1, keepdim=True)[1]
for i in range(len(target)):
if init_pred[i].item() != target[i].item():
continue
loss = F.nll_loss(output, target)
model.zero_grad()
loss.backward()
data_grad = data.grad.data
perturbed_data = fgsm_attack(data, epsilon, data_grad)
output = model(perturbed_data)
loss_after = F.nll_loss(output, target)
# print(f'loss: {loss}, loss after: {loss_after}')
final_pred = output.max(1, keepdim=True)[1]
for i in range(len(target)):
if final_pred[i].item() == target[i].item():
correct += 1
adv_examples.append((perturbed_data[i].cpu(), final_pred[i].item(), target[i].item()))
final_acc = correct / float(40*256)
print(f'Epsilon: {epsilon},\t,Accuracy: {correct}/{40*256}={final_acc*100:.2f}%')
return final_acc, adv_examples
def plot_examples(adv_examples, n):
for i in range(n):
img, pred, true = adv_examples[i]
plt.subplot(2, n//2, i + 1)
plt.imshow(img.squeeze().detach().numpy(), cmap='gray') # 添加 .detach().numpy()
plt.title(f'Pred: {pred}, True: {true}')
plt.axis('off')
plt.tight_layout()
plt.show()
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# loading dataset
test_dataset = MNIST(root='../Mnist', train=False, transform=transforms.ToTensor(), download=True)
train_dataset = MNIST(root='../Mnist', train=True, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=256, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=256, shuffle=True)
model = LeNet().to(device)
# training model
# train(train_loader, 100, device)
# loading trained model
pretrained_model = 'model/LeNet_mnist_model.pth'
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))
model.eval()
# attack process
accuracies = []
examples = []
# epsilons = [i*0.01 for i in range(0, 51, 5)]
# for eps in epsilons:
# acc, ex = attack(model, device, test_loader, eps)
# accuracies.append(acc)
# examples.append(ex)
acc, ex = attack(model, device, test_loader, 0.5)
accuracies.append(acc)
examples.append(ex)
print(examples[1], examples[2])参考资料
- Goodfellow, I. J., Shlens, J., & Szegedy, C. (2015). Explaining and harnessing adversarial examples.
- 腾讯安全朱雀实验室. (2022). AI安全:技术与实战. 电子工业出版社. ISBN: 978-7-121-43926-1.
Comments NOTHING